
Clickstream Data Analysis & Pavlovian Classical Conditioning
Pavlov’s discovery of classical conditioning remains one of the most important in psychology’s history. The basic premise is rather simple…

Pavlov’s discovery of classical conditioning remains one of the most important in psychology’s history. The basic premise is rather simple but conditional and unconditional stimuli and responses aren’t only manifest in canine species.
There is a reason why people respond to one UI version of an e-commerce store more than the other. However, advances in research methods and algorithms along with the capacity to transform clickstream data in real-time have made it possible to capture and identify these homo sapien conditional responses. How do you build a system like that?
Clickstream analysis is the process of collecting, analyzing, and reporting about which web pages a user visits, and can offer useful information about the usage characteristics of a website.
Some popular use cases for clickstream analysis include:
- A/B Testing: Statistically study how users of a web site are affected by changes from version A to B.
- Recommendation generation on shopping portals: Click patterns of users of a shopping portal website, indicate how a user was influenced into buying something. This information can be used as a recommendation generation for future such patterns of clicks.
-Targeted advertisement: Similar to recommendation generation, but tracking user clicks “across websites” and using that information to target advertisement in real-time.
-Trending topics: Clickstream can be used to study or report trending topics in real time. For a particular time quantum, display top items that gets the highest number of user clicks.
-Profit maximization by automatically adjusting pricing to demand levels and reap the benefits of trends.
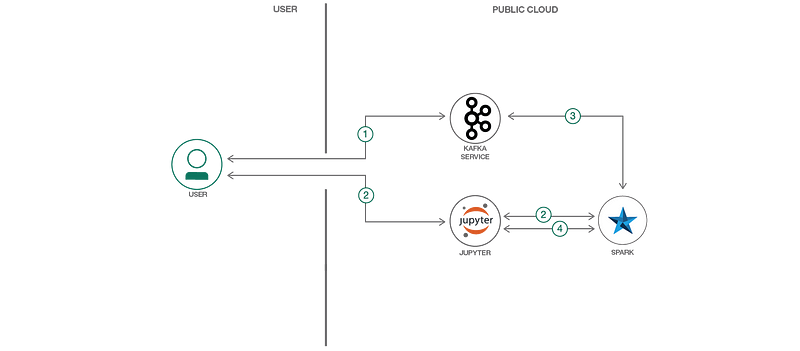
To set it up you will need Apache Kafka service and Apache Spark. You can use IBM’s Github page to follow the instructions to setup these pipelines and then analyze them in your RStudio or Jupyter notebooks.
Following are the components of the flow:
- IBM Watson Studio: Analyze data using RStudio, Jupyter, and Python in a configured, collaborative environment that includes IBM value-adds, such as managed Spark.
-Apache Spark: An open-source distributed computing framework that allows you to perform large-scale data processing.
-Apache Kafka: Kafka is used for building real-time data pipelines and streaming apps. It is designed to be horizontally scalable, fault-tolerant and fast.
-Jupyter Notebook: An open source web application that allows you to create and share documents that contain live code, equations, visualizations, and explanatory text.
-Event Streams: A scalable, high-throughput message bus. Wire micro-services together using open protocols.
While human brains can’t be decoded in a similar manner, its a lot easier to predict collective behaviors online with pretty decent accuracy. Quite a feat in social science i must say.